
こんなときに個人情報をマスキングしたい
- アプリケーションのテスト用に実際の個人情報満載のデータを使用したくない
- アンケート集計などの業務をアウトソーシングする際に不必要な個人情報はわたしたくない
今回紹介するのは関数で行う方法なので、最終的にコピペで特殊貼付けしてデータを上書きする手間が発生します。
その点はご注意ください。
なるべく関数初心者の方にも伝わるよう、ステップバイステップで解説してみます。
数字だけを隠す
今回紹介する関数のなかでは一番シンプルな形で、生年月日のマスキングを想定しています。
使用する関数はこちら
REGEXREPLACE(A1,"[0-9]","X")
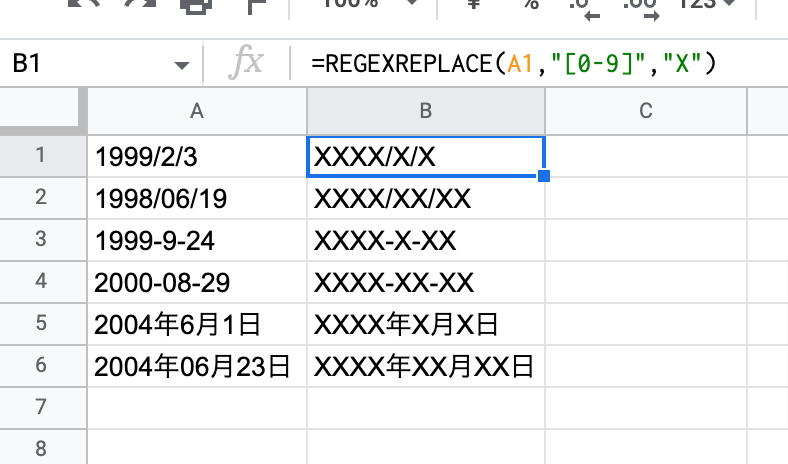
生年月日などの日付データはスラッシュ区切り、ハイフン区切り、もしくは年月日などのフォーマットがあります。
マスク済みデータを見ても、なんとなくどのフォーマットが使われているか、もしくは入り混じっているかがわかるようにしています。
関数は正規表現にマッチした部分を違う文字に置き換えるREGEXREPLACE関数を使用しています。
REGEXREPLACE – Google ドキュメント エディタ ヘルプ
正規表現を使用して、テキスト文字列の一部を別のテキスト文字列に置き換えます。
出典:https://support.google.com/docs/answer/3098245?hl=ja
A1のセルに書かれている文字列の中から0から9の半角数字にマッチした文字を「X」に置換しています。
数字を隠しつつ、末尾の2文字は見せる
ログイン用のSMSを送る電話番号やクレジットカード番号などを画面に表示するときによく見るマスクのパターンです。
関数はこちら。
LEFT(REGEXREPLACE(A1,"[0-9]","X"),LEN(A1)-2)&RIGHT(A1,2)

こちらもハイフンや()、国際電話のフォーマットのプラス(+)があるかないかがざっくり読み取れるようになっています。
関数をブレイクダウンして解説します。不要の方は読み飛ばしてください。
1.まずは文字列全体を末尾2文字とそれ以外の2つに分けます
RIGHT関数、LEFT関数とLEN関数を使って、文字列を2つに分割します。
RIGHT – Google ドキュメント エディタ ヘルプ
指定した文字列の末尾から部分文字列を返します。
出典:https://support.google.com/docs/answer/3094087?hl=ja
LEFT – Google ドキュメント エディタ ヘルプ
指定した文字列の先頭から部分文字列を返します。
出典:https://support.google.com/docs/answer/3094079?hl=ja
LEN – Google ドキュメント エディタ ヘルプ
文字列の長さを返します。
出典:https://support.google.com/docs/answer/3094081?hl=ja
まずは末尾の2文字は以下の関数で取得できます。
RIGHT(A1,2)
次に末尾2文字以外の文字列の取得についてですが、全体の文字数がハイフンありやカッコつきなどのフォーマットによって変化しても対応できるよう、LEN関数を使います。
LEN関数で全体の文字数を導き出して、そこから末尾の2文字分を減算。
LEN(A1)-2
LEFT関数にその数字を使って「先頭から末尾3文字目までの文字列」を取得します。
関数は以下の通りになります。
LEFT(A1,LEN(A1)-2)
2.それ以外の文字列から数字だけを置き換える
LEFT関数とLEN関数を使って導き出した文字列にREGEXREPLACE関数を使用して数字のみ置き換えます。
関数は以下の通りになります。
REGEXREPLACE(LEFT(A1,LEN(A1)-2),"[0-9]","X")
3.できた2つの関数を&でつなげる

LEFT(REGEXREPLACE(A1,"[0-9]","X"),LEN(A1)-2)&RIGHT(A1,2)
最初の3文字は表示して、その後の文字をマスクする
今回は末尾ではなく文字列の先頭を表示するパターンです。
使う関数は同じで、LEFTとRIGHTの中身をすこしアレンジします。
関数はこちら。
LEFT(A1,3)®EXREPLACE(RIGHT(A1,LEN(A1)-3),".","*")

左3文字をそのままにして、右側の全体文字数-3文字の文字列を正規表現で改行以外の全ての文字(“.”)を全角アスタリスクに置き換えています。
末尾1文字はそのまま表示、それ以外の文字列のスペース以外をマスクする
最後は日本人の氏名やふりがなを想定したマスキングです。
姓と名の間に区切りがあるかどうか、ある場合は半角スペースなのか全角スペースなのかを、マスクしつつもフォーマットを判別できる余地を残します。
関数はこちら
LEFT(REGEXREPLACE(A1,"[^ | ]","*"),LEN(A1)-1)&RIGHT(A1,1)
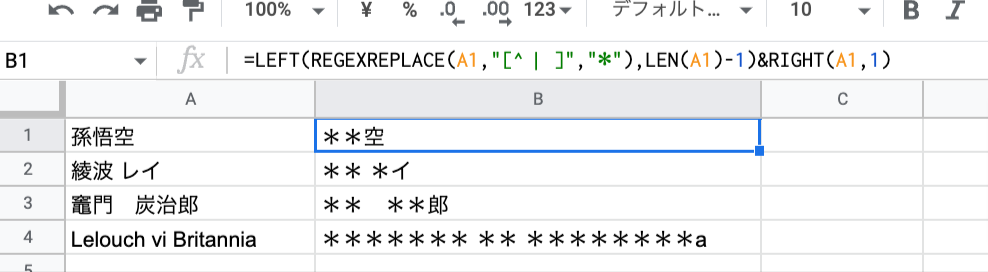
半角スペースまたは全角スペース以外を全角アスタリスクに置き換え。
次はマクロ化したい
冒頭にも書きましたが、関数を用いてマスキングする場合、関数用の列を追加し、関数の結果をコピーして、もとの列に特殊貼付けで値だけペーストする。みたいな手間が発生します。
できればこの手間も削減したいので、マクロ化できたらいいなぁと考えています。(予定は未定)